 第四章 XML、Tomcat、HTTP
第四章 XML、Tomcat、HTTP
# 第四章 XML_Tomcat10_HTTP
# 一、XML
XML(Extensible Markup Language,可扩展标记语言)是一种标准化的标记语言,被广泛应用于数据存储、配置管理、网络传输等领域。作为 W3C 推荐标准,XML 在企业级应用开发中扮演着重要角色。
XML 的核心价值:
可扩展性:XML 最大的优势在于其灵活的扩展能力。开发者可以根据具体业务需求自定义标签和结构,但这种灵活性建立在严格的语法规范基础之上。
规范性约束:虽然 XML 支持自定义,但实际项目中的 XML 配置文件都需要遵循特定的约束规范(DTD 或 Schema),这确保了配置的一致性和可验证性。
学习定位:在实际开发中,我们更多的是在现有 XML 配置文件基础上进行修改和定制,而非从零编写。因此,理解 XML 基本语法(良构规则)和特定框架的约束规范 (xsd) 同样重要。
HTML 与 XML 的几个关键区别:
- 宽容性:HTML 宽容 (标签可省略/不闭合),XML 严格 (大小写敏感,必须闭合)。
- 语义定义来源:HTML 由规范固定标签;XML 标签语义由业务/约束定义。
- 解析方式:HTML 浏览器内置容错解析;XML 常用 DOM/SAX/StAX/第三方库 (DOM4J) 解析,错误即失败。
- 主要用途:HTML 展示页面;XML 用于配置、数据交换、结构化存储 (被 JSON、YAML 等部分替代)。
常见初学误区:
- 误区 1:以为任意标签都能被框架识别。实际上不在约束中的标签通常被忽略或报错。
- 误区 2:把“良构”(well-formed) 与 “有效”(valid) 混淆。良构只保证语法正确;有效还需满足 DTD/Schema。
- 误区 3:忽略编码声明与实际文件编码不一致,导致解析乱码。
- 误区 4:属性与子元素随意选择。一般“标识/元数据”用属性,“层级/可扩展结构”用子元素。
- 误区 5:忘记根元素只能有一个。
# 1.1 常见配置文件类型
- properties:轻量键值对,常用于简单参数、数据库连接、组件 (如 Druid) 配置。
- XML:结构化 + 可扩展,适合复杂层级配置 (早期 Spring、MyBatis、Tomcat)。
- YAML:缩进语法,易读,适合 Spring Boot/容器化环境集中配置,支持多环境 profile。
- JSON:数据传输主力 (REST/前端),也用于部分配置 (前端工具链、VSCode)。
- 其他:INI/TOML/HOCON 等在特定生态中使用。
选择建议:结构简单用 properties;需要层级与约束用 XML;现代微服务优先 YAML;数据交互首选 JSON。
# 1.1.1 properties 配置文件
Properties 文件是 Java 生态系统中最传统的配置格式,以其简洁性著称。
示例配置
# 数据库连接配置
atguigu.jdbc.url=jdbc:mysql://localhost:3306/atguigu
atguigu.jdbc.driver=com.mysql.cj.jdbc.Driver
atguigu.jdbc.username=root
atguigu.jdbc.password=root
# 连接池配置
atguigu.jdbc.maxPoolSize=20
atguigu.jdbc.minPoolSize=5
2
3
4
5
6
7
8
9
语法与细节
- 键值分隔符:
=、:或首个空白;推荐统一使用=以减少歧义。 - 注释支持:行首
#或!。 - 空白折行:以反斜杠
\结尾可续行,续行首部前导空格被忽略。 - Unicode 转义:
\uXXXX表示 16 进制码位;现代环境存 UTF-8 时可避免过度使用。 - 转义字符:
\t、\n、\r、\f、\\、\:、\=等。 - 加载方式:
ResourceBundle会做国际化选择 (基于 locale),Properties#load(InputStream)直接读取。注意使用字节流时默认 ISO-8859-1,需自行处理编码 (建议使用Reader). - 不支持层级:常以“点分”约定伪层级,如
spring.datasource.url。
使用注意
- 避免在 value 中直接放多段结构化数据,超出简单键值需求时应迁移到 YAML 或 XML。
- 保持命名前缀一致以利于自动绑定 (如 Spring Boot ConfigurationProperties)。
- 避免敏感信息明文 (可使用外部化配置、Jasypt 加密或环境变量)。
适用场景
- 简单的应用配置
- 国际化资源文件
- 传统 Java 项目配置
# 1.1.2 xml 配置文件
XML 格式在企业级开发中应用最为广泛,特别是在 Spring、Maven、Tomcat 等主流框架中。
示例配置
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<database>
<connection>
<url>jdbc:mysql://localhost:3306/atguigu</url>
<driver>com.mysql.cj.jdbc.Driver</driver>
<username>root</username>
<password>root</password>
</connection>
<pool maxSize="20" minSize="5" />
</database>
<logging level="INFO" />
</configuration>
2
3
4
5
6
7
8
9
10
11
12
13
核心优势:
- 结构化表达:支持复杂的层次结构和数据关系
- 标准化验证:通过 DTD/Schema 进行格式验证
- 工具支持完善:IDE 提供智能提示和语法检查
- 国际标准:W3C 标准,跨平台兼容性好
技术特点:
- 可扩展性强:支持自定义标签和属性
- 数据类型丰富:可表达复杂的数据结构
- 命名空间支持:避免标签冲突
# 1.1.3 现代配置格式
YAML 格式(以 Spring Boot 为代表)
spring:
datasource:
url: jdbc:mysql://localhost:3306/atguigu
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
jpa:
hibernate:
ddl-auto: update
server:
port: 8080
2
3
4
5
6
7
8
9
10
11
JSON 格式(多用于前端和 API 配置)
{
"database": {
"url": "jdbc:mysql://localhost:3306/atguigu",
"driver": "com.mysql.cj.jdbc.Driver",
"credentials": {
"username": "root",
"password": "root"
}
},
"server": {
"port": 8080
}
}
2
3
4
5
6
7
8
9
10
11
12
13
格式选择建议
| 格式 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|
| Properties | 简单配置、国际化 | 语法简洁、解析快速 | 不支持嵌套、功能受限 |
| XML | 企业级框架配置 | 结构清晰、验证完善 | 语法冗余、学习成本高 |
| YAML | 现代微服务项目 | 语法简洁、可读性强 | 缩进敏感、调试困难 |
| JSON | API 配置、前端项目 | 标准化、工具支持好 | 不支持注释、可读性一般 |
# 1.2 XML 语法规范与约束机制
# 1.2.1 XML 基本语法
基本语法 (良构要求)
- XML 声明必须位于文件第一行第一列:
<?xml version="1.0" encoding="UTF-8"?>。 version属性指定 XML 版本(通常为 1.0),encoding属性指定字符编码(推荐 UTF-8)- 根元素唯一且包裹所有其他元素。
- 标签必须正确嵌套 (不交叉) 并闭合;空元素可用自闭合
<tag/>。 - 注释语法
<!-- ... -->,不可嵌套。 - 大小写敏感;推荐元素、属性使用小写或约定样式保持一致。
- 属性必须成对出现且带值:
attr="value",单双引号均可,但统一风格。 - 特殊字符需转义:
< > & ' "。 - 名称应具有语义性,便于理解,建议采用驼峰命名法或连字符分隔。
良构 vs 有效
- 良构 (Well-Formed):语法合法 (能被通用解析器读入)。
- 有效 (Valid):除良构外,还符合指定 DTD 或 XML Schema 的结构约束。
元素与属性选择
- 属性适合:标识、元数据、短且不可再分层信息 (例如
id="user-1"); - 子元素适合:层级结构、可扩展段落、多值集合;
- 不要用大量属性模拟嵌套结构,导致可读性差。
常见错误与注意事项
- 编码声明与文件实际编码不一致 (IDE 保存为 GBK 但声明 UTF-8)。
- 未正确关闭标签或多余空白导致解析异常。
- 在解析时忽视命名空间,错误获取元素 (需使用带命名空间前缀的解析方式)。
- 大文件直接 DOM 读取导致内存压力,可考虑 SAX/StAX/分片处理。
命名空间 (初学常忽略)
<root xmlns="http://example.com/schema" xmlns:x="http://example.com/x">
<item>...</item>
<x:item>命名空间区分</x:item>
</root>
2
3
4
用于避免不同来源的标签名冲突,解析时需通过命名空间 URI 精确匹配。
# 1.2.2 XML 约束机制
XML 约束确保文档结构的一致性和有效性,主要包括 DTD 和 Schema 两种约束方式。
- DTD:较早期,语法简单但类型支持弱,不支持命名空间丰富类型;
- XML Schema (XSD):基于 XML 自描述,支持命名空间与丰富数据类型,是现代 Java 框架主流选择。 作用:编辑器基于约束提供自动补全与校验,确保配置文件有效。
Schema 约束示例(以 web.xml 为例):
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee
http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
<display-name>MyWebApp</display-name>
<servlet>
<servlet-name>dispatcher</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
</servlet>
</web-app>
2
3
4
5
6
7
8
9
10
11
12
13
14
约束机制的作用
- 结构验证:确保标签的层次关系正确
- 类型检查:验证属性值的数据类型
- 完整性校验:检查必需元素是否存在
- IDE 智能提示:提供代码补全和语法检查
# 1.3 DOM4J XML 解析技术
DOM4J 是 Java 平台上性能优异的 XML 解析库,广泛应用于企业级项目中。相比于原生的 DOM 和 SAX 解析器,DOM4J 提供了更加简洁的 API 和更好的性能表现。
# 1.3.1 DOM4J 技术架构
DOM4J 采用 树形结构 来表示 XML 文档,提供了丰富的导航和操作 API。
核心组件:
- SAXReader:XML 文档解析器
- Document:XML 文档对象模型
- Element:XML 元素节点
- Attribute:元素属性对象
# 1.3.2 DOM4J 开发流程
标准开发步骤:
- 环境准备:导入
dom4j.jar依赖 - 创建解析器:实例化 SAXReader 对象
- 解析文档:获取 Document 对象
- 获取根节点:访问 XML 根元素
- 遍历处理:获取和处理子节点数据
# 1.3.3 DOM4J 核心 API 详解
1. 创建解析器
// 创建 SAXReader 解析器实例
SAXReader saxReader = new SAXReader();
2
2. 解析 XML 文档
// 通过字节输入流解析 XML 文件
InputStream inputStream = new FileInputStream("config.xml");
Document document = saxReader.read(inputStream);
// 也可以直接传入文件对象
File xmlFile = new File("config.xml");
Document document = saxReader.read(xmlFile);
2
3
4
5
6
7
3. 获取文档根元素
Element rootElement = document.getRootElement();
System.out.println("根元素名称:" + rootElement.getName());
2
4. 元素导航操作
// 获取所有直接子元素
List<Element> childElements = rootElement.elements();
// 获取指定名称的子元素
List<Element> studentElements = rootElement.elements("student");
// 获取第一个指定名称的子元素
Element firstStudent = rootElement.element("student");
2
3
4
5
6
7
8
5. 数据提取操作
// 获取元素的文本内容
String textContent = element.getText();
String trimmedText = element.getTextTrim(); // 去除首尾空白
// 获取元素属性值
String attributeValue = element.attributeValue("属性名");
// 获取所有属性
List<Attribute> attributes = element.attributes();
2
3
4
5
6
7
8
9
# 1.3.4 实际应用案例
示例 XML 配置文件(students.xml):
<?xml version="1.0" encoding="UTF-8"?>
<class name="高三一班" teacher="张老师">
<student id="001" gender="male">
<name>张三</name>
<age>18</age>
<score>
<math>95</math>
<english>87</english>
<chinese>92</chinese>
</score>
</student>
<student id="002" gender="female">
<name>李四</name>
<age>17</age>
<score>
<math>88</math>
<english>94</english>
<chinese>89</chinese>
</score>
</student>
</class>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
完整解析代码示例:
import org.dom4j.*;
import org.dom4j.io.SAXReader;
import java.io.InputStream;
import java.util.List;
public class XmlParserDemo {
public static void main(String[] args) {
try {
// 1. 创建解析器
SAXReader reader = new SAXReader();
// 2. 获取XML文件输入流
InputStream inputStream = XmlParserDemo.class.getClassLoader()
.getResourceAsStream("students.xml");
// 3. 解析XML文档
Document document = reader.read(inputStream);
// 4. 获取根元素
Element classElement = document.getRootElement();
System.out.println("班级:" + classElement.attributeValue("name"));
System.out.println("班主任:" + classElement.attributeValue("teacher"));
// 5. 遍历学生信息
List<Element> students = classElement.elements("student");
for (Element student : students) {
parseStudentInfo(student);
System.out.println("-------------------");
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 解析单个学生信息
*/
private static void parseStudentInfo(Element student) {
// 获取学生基本信息
String id = student.attributeValue("id");
String gender = student.attributeValue("gender");
String name = student.element("name").getText();
String age = student.element("age").getText();
System.out.println("学号:" + id);
System.out.println("姓名:" + name);
System.out.println("年龄:" + age);
System.out.println("性别:" + gender);
// 解析成绩信息
Element scoreElement = student.element("score");
if (scoreElement != null) {
String math = scoreElement.element("math").getText();
String english = scoreElement.element("english").getText();
String chinese = scoreElement.element("chinese").getText();
System.out.println("数学成绩:" + math);
System.out.println("英语成绩:" + english);
System.out.println("语文成绩:" + chinese);
// 计算平均分
double avgScore = (Double.parseDouble(math) +
Double.parseDouble(english) +
Double.parseDouble(chinese)) / 3.0;
System.out.printf("平均分:%.2f%n", avgScore);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
运行结果:
班级:高三一班
班主任:张老师
学号:001
姓名:张三
年龄:18
性别:male
数学成绩:95
英语成绩:87
语文成绩:92
平均分:91.33
-------------------
学号:002
姓名:李四
年龄:17
性别:female
数学成绩:88
英语成绩:94
语文成绩:89
平均分:90.33
-------------------
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 1.3.5 DOM4J 实践技巧
异常处理最佳实践
public class SafeXmlParser {
public static Document parseXmlSafely(String filePath) {
SAXReader reader = new SAXReader();
InputStream inputStream = null;
try {
inputStream = new FileInputStream(filePath);
return reader.read(inputStream);
} catch (DocumentException e) {
System.err.println("XML解析异常:" + e.getMessage());
return null;
} catch (Exception e) {
System.err.println("文件读取异常:" + e.getMessage());
return null;
} finally {
if (inputStream != null) {
try {
inputStream.close();
} catch (Exception e) {
System.err.println("关闭流异常:" + e.getMessage());
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
性能优化建议
- 复用解析器:SAXReader 对象可以重复使用
- 及时关闭流:使用 try-with-resources 语句
- 避免频繁解析:对于静态配置,可以缓存解析结果
- 选择合适的 API:根据需求选择
getText()或getTextTrim()
# 二、Tomcat 服务器深度解析
# 2.1 Web 服务器技术基础
# 2.1.1 Web 服务器架构概览
Web 服务器是现代互联网应用的核心基础设施,负责处理 HTTP 请求并返回相应的资源。
技术组成:
- 硬件层面:提供计算资源和网络连接的物理服务器
- 软件层面:处理 HTTP 协议、管理 Web 资源的服务器程序
- 网络层面:实现客户端与服务器间的通信桥梁
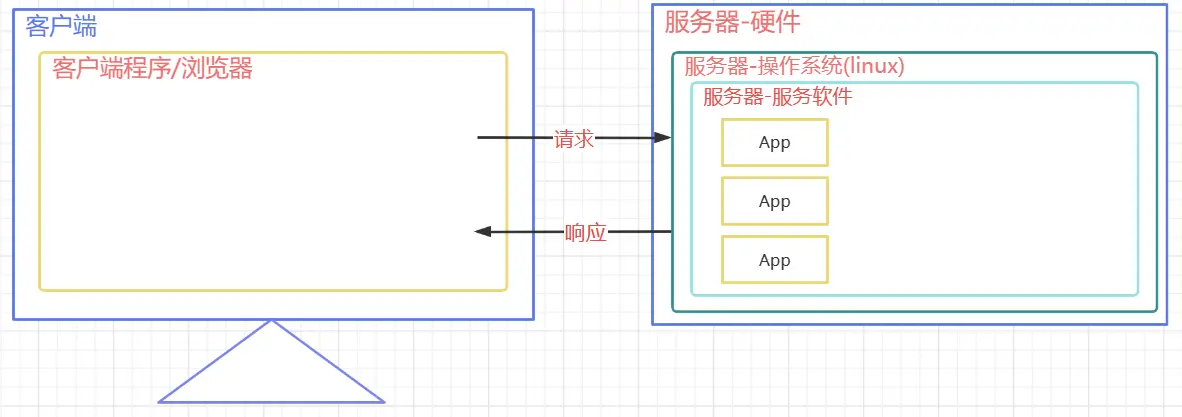
工作原理
- 监听端口:服务器在指定端口监听客户端请求
- 解析请求:解析 HTTP 请求报文,提取资源路径和参数
- 资源定位:根据 URL 映射到具体的文件或程序
- 响应生成:处理业务逻辑,生成 HTTP 响应
- 返回结果:将响应数据发送回客户端
# 2.1.2 JavaWeb 服务器生态对比
| 服务器 | 开发商 | 特点 | 适用场景 | 许可证 |
|---|---|---|---|---|
| Tomcat | Apache | 轻量级、开源、广泛使用 | 中小型企业应用 | 免费 |
| Jetty | Eclipse | 更轻量、嵌入式友好 | 微服务、测试环境 | 免费 |
| JBoss/WildFly | RedHat | 完整 JavaEE 支持 | 企业级应用 | 免费 |
| WebLogic | Oracle | 商业级、高性能 | 大型企业应用 | 商业许可 |
| WebSphere | IBM | 企业级、高可用 | 大型企业应用 | 商业许可 |
选择建议
- 学习阶段:推荐 Tomcat,文档完善,社区活跃
- 生产环境:根据项目规模和技术栈选择
- 微服务架构:考虑 Jetty 或嵌入式 Tomcat
# 2.2 Tomcat 服务器
# 2.2.1 简介
Tomcat 是 Apache 软件基金会 的顶级项目,作为 Servlet 容器 的参考实现,在 JavaWeb 开发领域占据重要地位。
核心优势
- 标准兼容:完全符合 Servlet 和 JSP 规范
- 开源免费:降低项目成本,避免商业许可限制
- 性能优异:经过多年优化,支持高并发访问
- 社区活跃:丰富的文档资源和社区支持
- 易于集成:与主流 IDE 和框架无缝集成
架构组件
- Server:Tomcat 实例的顶层容器
- Service:包含多个连接器的服务组件
- Connector:处理不同协议的连接器(HTTP、AJP 等)
- Engine:Servlet 引擎,处理请求的核心组件
- Host:虚拟主机,支持多域名部署
- Context:Web 应用上下文,代表单个 Web 应用
# 2.2.2 版本选择与兼容性
版本演进历程
版本选择建议
- 学习环境:推荐 Tomcat 10.x,支持最新 Jakarta EE 规范
- 生产环境:根据现有技术栈选择,Tomcat 9.x 仍是主流
- 新项目:优先选择 Tomcat 10.x 或更高版本
JavaEE 与 Jakarta EE 版本对应
| Servlet 版本 | EE 版本 | 命名空间 | 说明 |
|---|---|---|---|
| 6.1 | Jakarta EE 11 | jakarta.* | 最新规范 |
| 6.0 | Jakarta EE 10 | jakarta.* | 推荐使用 |
| 5.0 | Jakarta EE 9/9.1 | jakarta.* | 命名空间迁移版本 |
| 4.0 | Java EE 8 | javax.* | 传统版本 |
Tomcat 版本与 JDK 兼容性
| Tomcat 版本 | Servlet 版本 | 最低 JDK | 推荐 JDK |
|---|---|---|---|
| 11.0.x | 6.1 | JDK 17 | JDK 21+ |
| 10.1.x | 6.0 | JDK 11 | JDK 17+ |
| 9.0.x | 4.0 | JDK 8 | JDK 11+ |
| 8.5.x | 3.1 | JDK 7 | JDK 8+ |
重要变化
从 Tomcat 10 开始,包名从 javax.* 迁移到 jakarta.*,这是一个重大变化,需要注意代码兼容性。
# 2.2.3 安装部署实践
下载与选择
- Tomcat 官方网站:http://tomcat.apache.org/ (opens new window)
- 安装版:需要安装,一般不考虑使用。
- 解压版:直接解压缩使用,推荐使用的版本。
安装环境准备
- JDK 环境配置
# Windows 环境变量配置 JAVA_HOME=C:\Program Files\Java\jdk-17 PATH=%JAVA_HOME%\bin;%PATH% # 验证 JDK 安装 java -version javac -version1
2
3
4
5
6
7 - 解压 tomcat 到非中文无空格目录
- 执行
bin/startup.bat(Windows)或bin/startup.sh(Linux/Mac)启动服务。 - 在浏览器中访问
http://localhost:8080,验证 Tomcat 是否正常运行。 - 关闭服务
- 方式一:直接关闭控制台窗口
- 方式二:执行
bin/shutdown.bat优雅关闭
- 解决中文乱码问题:修改
conf/logging.properties文件,将所有UTF-8改为GBK
环境配置建议
- 使用 UTF-8 编码的现代 IDE 开发时,建议保持日志编码为 UTF-8
- 在 Windows 命令行中查看日志时,可临时修改为 GBK 编码
- 生产环境建议统一使用 UTF-8 编码
# 2.3 Tomcat 目录结构深度解析
Tomcat 的目录结构设计遵循职责分离原则,每个目录都有明确的功能定位。
# 2.3.1 核心目录结构
以 C:\Program4java\apache-tomcat-10.1.7 为例,这是 Tomcat 的安装根目录。
apache-tomcat-10.1.7/
├── bin/ # 可执行文件目录
├── conf/ # 配置文件目录
├── lib/ # 核心类库目录
├── logs/ # 日志文件目录
├── temp/ # 临时文件目录
├── webapps/ # Web应用部署目录
├── work/ # 运行时工作目录
├── LICENSE # 许可证文件
└── NOTICE # 版权声明文件
2
3
4
5
6
7
8
9
10
# 2.3.2 关键目录详解
1. bin 目录 - 可执行文件
| 文件名 | 用途 | 平台 |
|---|---|---|
startup.bat/sh | 启动 Tomcat | Windows/Unix |
shutdown.bat/sh | 关闭 Tomcat | Windows/Unix |
catalina.bat/sh | Tomcat 主控脚本 | Windows/Unix |
version.bat/sh | 显示版本信息 | Windows/Unix |
2. conf 目录 - 配置管理
重要配置文件
conf 目录包含 Tomcat 的核心配置文件,修改需谨慎操作。
| 配置文件 | 功能描述 | 重要程度 |
|---|---|---|
| server.xml | 服务器主配置文件,包含端口、虚拟主机等 | ⭐⭐⭐⭐⭐ |
| web.xml | 全局 Web 应用配置,MIME 类型定义 | ⭐⭐⭐⭐ |
| tomcat-users.xml | 用户权限管理配置 | ⭐⭐⭐ |
| context.xml | 全局上下文配置 | ⭐⭐⭐ |
| logging.properties | 日志配置文件 | ⭐⭐ |
server.xml 关键配置示例
<Server port="8005" shutdown="SHUTDOWN">
<Service name="Catalina">
<!-- HTTP 连接器配置 -->
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
<!-- 引擎配置 -->
<Engine name="Catalina" defaultHost="localhost">
<!-- 虚拟主机配置 -->
<Host name="localhost" appBase="webapps"
unpackWARs="true" autoDeploy="true">
</Host>
</Engine>
</Service>
</Server>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
tomcat-users.xml 用户配置
<tomcat-users xmlns="http://tomcat.apache.org/xml"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://tomcat.apache.org/xml tomcat-users.xsd"
version="1.0">
<!-- 定义角色 -->
<role rolename="manager-gui"/>
<role rolename="manager-script"/>
<role rolename="admin-gui"/>
<!-- 定义用户 -->
<user username="admin"
password="admin"
roles="manager-gui,manager-script,admin-gui"/>
</tomcat-users>
2
3
4
5
6
7
8
9
10
11
12
13
14
3. lib 目录 - 核心类库
存放 Tomcat 核心 JAR 包和全局共享库:
- catalina.jar:Tomcat 核心引擎
- servlet-api.jar:Servlet API 实现
- jsp-api.jar:JSP API 实现
- el-api.jar:EL 表达式 API
类库管理建议
- 不建议在 lib 目录放置应用特定的 JAR 包
- 应用依赖的 JAR 包应放在
WEB-INF/lib目录下 - 仅放置 Tomcat 运行必需的核心库
4. webapps 目录 - 应用部署
Web 应用的默认部署目录,每个子目录代表一个独立的 Web 应用:
webapps/
├── ROOT/ # 根应用 (http://localhost:8080/)
├── examples/ # 示例应用 (http://localhost:8080/examples/)
├── docs/ # 文档应用
├── manager/ # 管理应用
└── host-manager/ # 主机管理应用
2
3
4
5
6
URL 映射规则:
http://localhost:8080/→webapps/ROOT/http://localhost:8080/myapp/→webapps/myapp/
5. work 目录 - 运行时工作空间
存放 JSP 编译后的 Java 源码和字节码文件:
work/Catalina/localhost/myapp/
├── org/apache/jsp/
│ ├── index_jsp.java # JSP 转换的 Java 源码
│ └── index_jsp.class # 编译后的字节码
2
3
4
6. logs 目录 - 日志管理
| 日志文件 | 内容描述 |
|---|---|
catalina.out | 标准输出日志 |
catalina.yyyy-mm-dd.log | Catalina 引擎日志 |
localhost.yyyy-mm-dd.log | 本地主机访问日志 |
manager.yyyy-mm-dd.log | 管理应用日志 |
# 2.3.3 目录权限与安全
安全配置建议
- 最小权限原则:仅给予 Tomcat 运行所需的最小权限
- 目录保护:限制对 conf、lib 等敏感目录的访问
- 日志管理:定期清理和备份日志文件
- 应用隔离:不同应用使用独立的数据库和资源
# 2.4 Web 项目标准结构
# 2.4.1 JavaWeb 项目规范结构
一个符合规范的 Web 项目必须遵循特定的目录结构,这是 Servlet 容器的基本要求。
myapp/ # 应用根目录
├── index.html # 默认欢迎页(可选)
├── static/ # 静态资源目录(约定)
│ ├── css/ # 样式文件
│ ├── js/ # JavaScript 文件
│ ├── images/ # 图片资源
│ └── fonts/ # 字体文件
├── WEB-INF/ # 受保护的资源目录(必需)
│ ├── web.xml # 部署描述符(必需)
│ ├── classes/ # 编译后的 Java 类(必需)
│ │ ├── com/ # Java 包结构
│ │ │ └── example/
│ │ │ ├── servlet/
│ │ │ ├── service/
│ │ │ └── util/
│ │ └── config.properties # 配置文件
│ └── lib/ # 项目依赖的 JAR 包(必需)
│ ├── mysql-connector.jar
│ ├── jackson-core.jar
│ └── commons-lang3.jar
└── META-INF/ # 元信息目录(可选)
└── MANIFEST.MF # 清单文件
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 2.4.2 目录功能详解
1. WEB-INF 目录特性
安全保护
WEB-INF 目录及其子目录的内容不能通过 URL 直接访问,这是 Servlet 规范的安全机制。
- classes 目录:存放编译后的 Java 字节码文件和配置文件
- lib 目录:存放项目依赖的第三方 JAR 包
- web.xml 文件:Web 应用的部署描述符
2. 静态资源目录
- static 目录:约定俗成的静态资源目录名
- 可直接通过 URL 访问:
http://domain/app/static/css/style.css
3. 欢迎页面配置
默认欢迎页面优先级:index.html > index.htm > index.jsp
# 2.4.3 URL 映射关系
映射规则解析:
http://localhost:8080/myapp/static/css/style.css
│ │ │ │ │ │ │
│ │ │ │ │ │ └─ 文件名
│ │ │ │ │ └───── 目录名
│ │ │ │ └──────────── 静态资源目录
│ │ │ └─────────────────── 应用上下文路径
│ │ └──────────────────────── 端口号
│ └─────────────────────────────────── 主机名
└───────────────────────────────────────── 协议
2
3
4
5
6
7
8
9
# 2.5 Web 项目部署策略
# 2.5.1 部署方式对比
| 部署方式 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|
| 目录部署 | 开发测试 | 部署简单,便于调试 | 文件散乱,不便传输 |
| WAR 包部署 | 生产环境 | 文件整合,版本管理好 | 热部署需要重启 |
| 外部路径部署 | 特殊需求 | 灵活的目录结构 | 配置复杂,维护困难 |
# 2.5.2 详细部署实践
方式一:目录直接部署
将编译完成的项目目录直接放置在 webapps 目录下:
# 复制项目到 webapps
cp -r myapp $CATALINA_HOME/webapps/
# 访问地址
http://localhost:8080/myapp/
2
3
4
5
方式二:WAR 包部署
# 打包项目
jar -cvf myapp.war -C myapp/ .
# 部署到 Tomcat
cp myapp.war $CATALINA_HOME/webapps/
# Tomcat 启动时自动解压
# 访问地址同上
2
3
4
5
6
7
8
方式三:外部路径部署
准备项目目录
创建上下文配置文件
在 conf/Catalina/localhost/ 目录下创建 app.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!--
path: 应用的访问路径(上下文路径)
docBase: 应用在磁盘中的实际物理路径
reloadable: 是否监控类文件变化并自动重新加载
-->
<Context path="/app"
docBase="D:\mywebapps\app"
reloadable="true">
<!-- 数据源配置示例 -->
<Resource name="jdbc/myDataSource"
auth="Container"
type="javax.sql.DataSource"
maxTotal="20"
maxIdle="10"
maxWaitMillis="-1"
username="root"
password="password"
driverClassName="com.mysql.cj.jdbc.Driver"
url="jdbc:mysql://localhost:3306/mydb"/>
</Context>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
配置参数说明:
- path:浏览器访问的应用路径
- docBase:应用的物理磁盘路径(绝对路径)
- reloadable:开发环境可设为 true,生产环境建议 false
# 2.5.3 部署最佳实践
开发环境:
- 使用 IDE 集成部署,支持热重载
- 启用 reloadable 属性便于调试
- 配置详细的日志输出
测试环境:
- 使用 WAR 包部署,模拟生产环境
- 配置性能监控和日志收集
- 进行负载测试和安全扫描
生产环境:
- 使用自动化部署脚本
- 配置集群和负载均衡
- 实施严格的安全策略和监控
# 2.6 IDEA 集成开发环境配置
# 2.6.1 Tomcat 服务器关联
在 IDEA 中集成 Tomcat 可以显著提升开发效率,实现代码修改的实时生效。
配置步骤:
- 打开设置面板:通过
File → Settings(Windows)或IntelliJ IDEA → Preferences(Mac)打开设置。 - 配置应用服务器:导航到
Build, Execution, Deployment → Application Servers,点击+号添加服务器。 - 选择 Tomcat 类型
- 指定 Tomcat 安装路径:选择本地 Tomcat 的安装根目录。
- 确认配置
- 关联完成
# 2.6.2 Web 项目创建
项目创建策略:推荐创建空项目作为工作空间,可以容纳多个 Module,便于项目管理。
项目配置检查:验证 JDK 版本、语言级别和输出目录设置
创建 Java Module
添加 Web 框架支持:
- 添加 Tomcat 依赖
- 启用 Web 框架支持:右键点击 Module,选择
Add Framework Support - 选择 Web Application 注意 Version(Version 5.0),勾选 Create web.xml
- 删除 index.jsp ,替换为 index.html
- 处理配置文件
- 在工程下创建 resources 目录,专门用于存放配置文件(都放在 src 下也行,单独存放可以尽量避免文件集中存放造成的混乱)
- 标记目录为资源目录,不标记的话则该目录不参与编译
- 处理依赖 jar 包问题
- 在 WEB-INF 下创建 lib 目录
- 必须在 WEB-INF 下,且目录名必须叫 lib!!!
- 复制 jar 文件进入 lib 目录
- 将 lib 目录添加为当前项目的依赖,后续可以用 maven 统一解决
- 环境级别推荐选择 module 级别,降低对其他项目的影响,name 可以空着不写
# 2.6.3 IDEA 部署-运行 web 项目
- 检查 idea 是否识别 modules 为 web 项目并存在将项目构建成发布结构的配置
- 就是检查工程目录下,web 目录有没有特殊的识别标记
- 以及 artifacts 下,有没有对应 _war_exploded,如果没有,就点击+号添加
- 点击向下箭头,出现 Edit Configurations 选项
- 出现运行配置界面
- 点击+号,添加本地 tomcat 服务器
- 因为 IDEA 只关联了一个 Tomcat,红色部分就只有一个 Tomcat 可选
- 选择 Deployment,通过+添加要部署到 Tomcat 中的 artifact
- applicationContext 中是默认的项目上下文路径,也就是 url 中需要输入的路径,这里可以自己定义,可以和工程名称不一样,也可以不写,但是要保留
/,这里暂时就用默认的 - 点击 apply 应用后,回到 Server 部分。After Launch 是配置启动成功后,是否默认自动打开浏览器并输入 URL 中的地址,HTTP port 是 Http 连接器目前占用的端口号
- 点击 OK 后,启动项目,访问测试
- 绿色箭头是正常运行模式
- "小虫子"是 debug 运行模式
- 点击后,查看日志状态是否有异常
- 浏览器自动打开并自动访问了 index.html 欢迎页
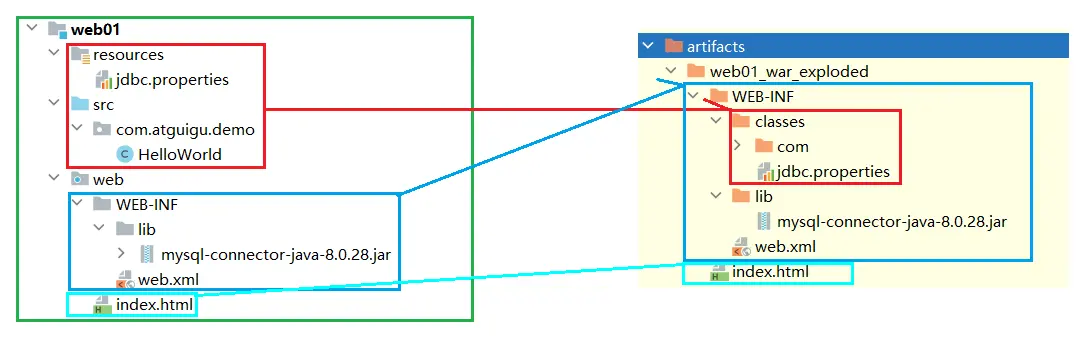
工程结构和可以发布的项目结构之间的目录对应关系
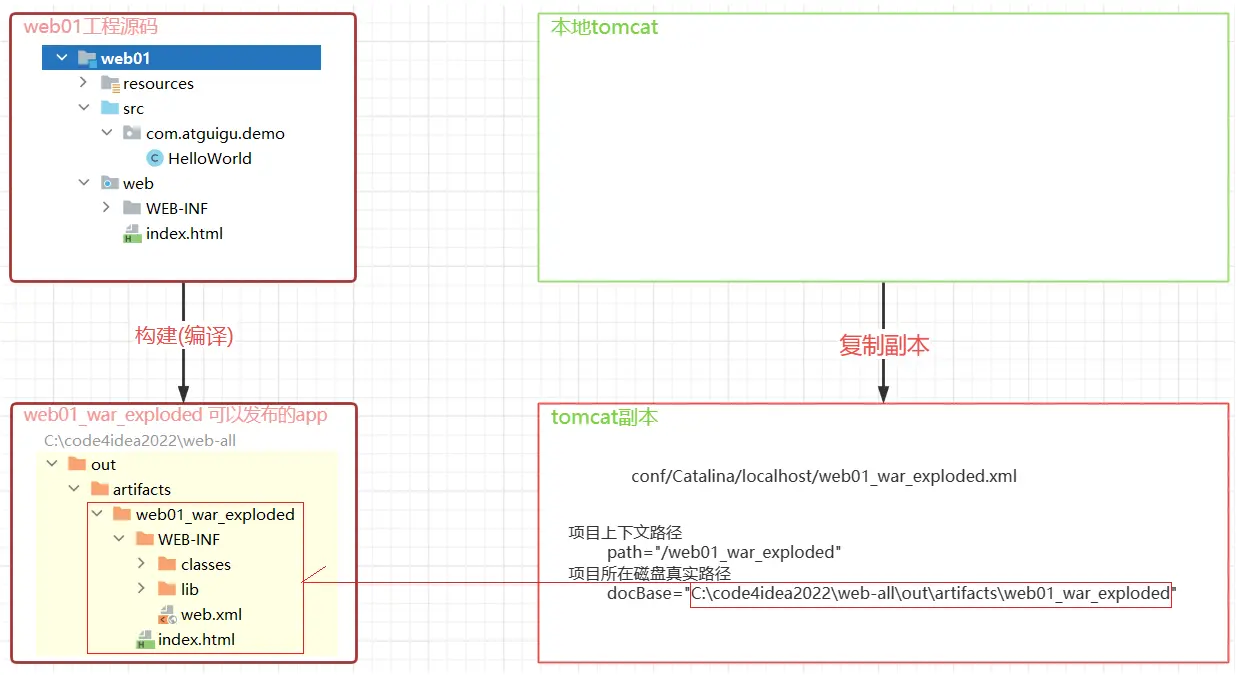
IDEA 部署并运行项目的原理:
- idea 并没有直接进将编译好的项目放入 tomcat 的 webapps 中
- idea 根据关联的 tomcat,创建了一个 tomcat 副本,将项目部署到了这个副本中
- idea 的 tomcat 副本在
C:\用户\当前用户\AppData\Local\JetBrains\IntelliJIdea2024.1\tomcat\中 - idea 的 tomcat 副本并不是一个完整的 tomcat,副本里只是准备了和当前项目相关的配置文件而已
- idea 启动 tomcat 时,是让本地 tomcat 程序按照 tomcat 副本里的配置文件运行
- idea 的 tomcat 副本部署项目的模式是通过
conf/Catalina/localhost/*.xml配置文件的形式实现项目部署的
# 三、HTTP 协议深度解析
# 3.1 HTTP 协议核心原理
# 3.1.1 HTTP 协议概述
HTTP(Hypertext Transfer Protocol,超文本传输协议) 是现代互联网的基础通信协议,位于 OSI 模型的应用层,专门用于在 Web 浏览器和服务器之间传输超媒体文档。
核心特征:
- 无状态协议:每个请求都是独立的,服务器不保存客户端的状态信息
- 明文传输:HTTP 本身不加密,数据以明文形式传输(HTTPS 提供加密)
- 请求-响应模式:采用严格的客户端请求、服务器响应的交互模式
- 灵活扩展:支持多种数据格式和传输方式
技术定位:HTTP 协议的学习重点在于理解报文格式和通信规则。客户端发送给服务器的称为请求报文,服务器返回给客户端的称为响应报文。
# 3.1.2 HTTP 协议发展历程
HTTP/0.9(1991 年)- 原始版本
- 特点:极简协议,仅支持 GET 方法
- 局限性:只能传输 HTML 文档,无请求头概念
- 历史意义:奠定了 Web 通信的基础架构
GET /index.html
HTTP/1.0(1996 年)- 功能扩展
- 核心改进:
- 引入请求头和响应头机制
- 新增 HEAD、POST 方法
- 支持多种 MIME 类型
- 添加状态码系统
GET /index.html HTTP/1.0
Host: www.example.com
User-Agent: Mozilla/4.0
2
3
HTTP/1.1(1997 年)- 标准化里程碑
HTTP/1.1 是使用最广泛的版本,至今仍是 Web 开发的主流协议。
关键特性:
- 持久连接:
Connection: keep-alive,减少连接开销 - 管道化请求:在同一连接上发送多个请求
- 虚拟主机:支持基于 Host 头的虚拟主机
- 缓存机制:完善的缓存控制策略
- 分块传输:
Transfer-Encoding: chunked
HTTP/2(2015 年)- 性能革命
- 二进制协议:提升解析效率和传输性能
- 多路复用:单连接并行处理多个请求/响应
- 头部压缩:使用 HPACK 算法减少头部冗余
- 服务器推送:主动推送客户端可能需要的资源
- 强制 HTTPS:提升网络安全性
HTTP/3(2021 年)- 未来标准
- 基于 QUIC:替代 TCP,减少连接延迟
- 改进的多路复用:解决 TCP 队头阻塞问题
- 更强的安全性:内置加密和身份验证
- 移动友好:更好的网络切换支持
# 3.1.3 HTTP 通信特性
1. 无状态特性
# 第一个请求
GET /login HTTP/1.1
Host: example.com
# 第二个请求(服务器不记住上一个请求)
GET /profile HTTP/1.1
Host: example.com
2
3
4
5
6
7
解决方案:
- Cookie:客户端存储状态信息
- Session:服务器端状态管理
- Token:无状态身份验证
2. 连接管理演进
| 版本 | 连接方式 | 特点 | 性能影响 |
|---|---|---|---|
| HTTP/1.0 | 短连接 | 每次请求建立新连接 | 连接开销大 |
| HTTP/1.1 | 持久连接 | 复用 TCP 连接 | 减少握手开销 |
| HTTP/2 | 多路复用 | 单连接并行传输 | 显著提升并发性能 |

3. HTTP/1.1 vs HTTP/1.0 对比
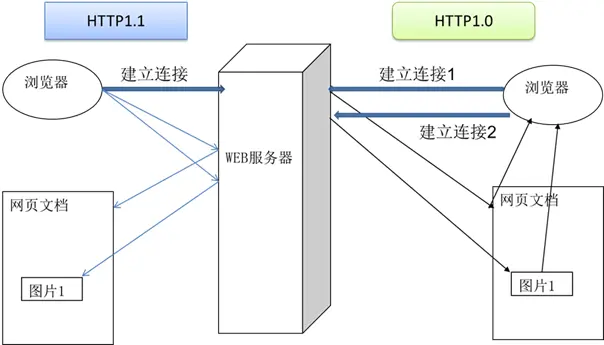
性能优化体现:
- 资源复用:一个连接可以传输多个资源
- 减少延迟:避免重复的 TCP 三次握手
- 带宽利用率:更高效的网络资源使用
# 3.1.4 开发者工具应用
现代浏览器的开发者工具是学习和调试 HTTP 协议的重要手段。
实用功能:
- Network 面板:
- 查看所有 HTTP 请求/响应
- 分析请求时间线和性能瓶颈
- 检查请求头、响应头详情
- 请求过滤:
- 按资源类型过滤(JS、CSS、Images 等)
- 按状态码过滤异常请求
- 搜索特定的请求 URL
- 性能分析:
- Timing 分析:DNS 查询、连接建立、数据传输时间
- Size 分析:请求大小、响应大小、压缩效果
- Waterfall 图:可视化请求并发和依赖关系
调试技巧:
// 在控制台中模拟 HTTP 请求
fetch('/api/data', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': 'Bearer token123'
},
body: JSON.stringify({ name: 'example' })
})
.then(response => response.json())
.then(data => console.log(data));
2
3
4
5
6
7
8
9
10
11
# 3.2 HTTP 报文深度分析
# 3.2.1 报文结构基础
HTTP 报文采用规范化的结构设计,确保客户端和服务器能够准确解析通信内容。
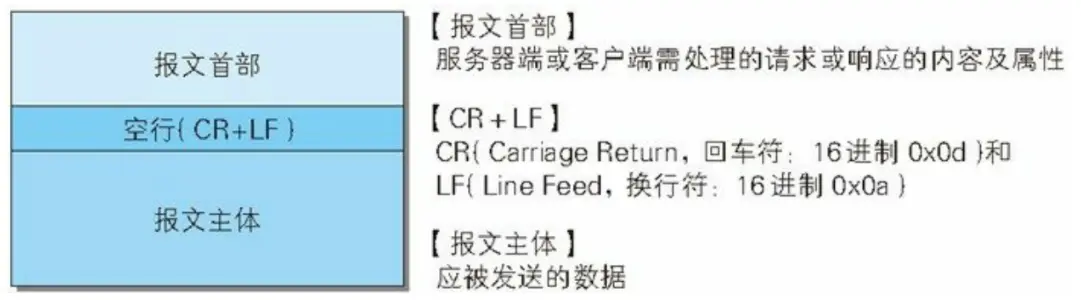
报文部首可以继续细分为 "行" 和 "头":
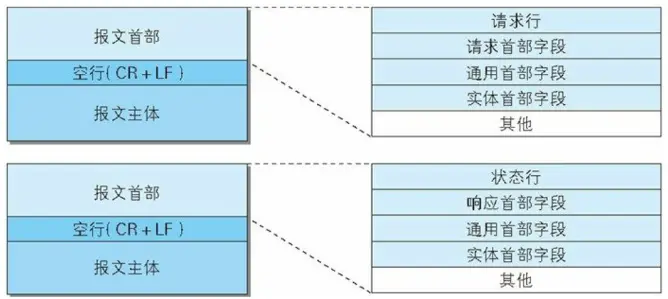
结构层次:
- 报文首部:包含请求/响应行和头部字段
- 空行:分隔首部和主体的重要标识
- 报文主体:实际传输的数据内容
# 3.2.2 HTTP 请求报文详解
请求报文是客户端向服务器发送的数据包,包含了客户端的意图和相关信息。
请求报文格式:
请求行: 方法 资源路径 协议版本
请求头: Header-Name: Header-Value
空行:
请求体: 实际数据(仅POST等方法)
2
3
4
# 3.2.3 GET 请求深度分析
GET 请求特征:
GET 请求的设计理念
GET 方法遵循 幂等性 原则,多次执行相同的 GET 请求应该产生相同的结果,且不会修改服务器状态。
1. 请求行结构
GET /05_web_tomcat/login_success.html?username=admin&password=123213 HTTP/1.1
│ │ │ │
│ │ │ └─ 协议版本
│ │ └─ 查询参数(Query String)
│ └─ 资源路径
└─ 请求方法
2
3
4
5
6
2. 重要请求头详解
# 主机信息
Host: localhost:8080
# 说明:指定目标服务器的主机名和端口,支持虚拟主机
# 连接管理
Connection: keep-alive
# 说明:保持连接活跃,支持连接复用
# 安全升级
Upgrade-Insecure-Requests: 1
# 说明:建议服务器将HTTP连接升级为HTTPS
# 用户代理信息
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36
# 说明:客户端信息,包括浏览器类型、版本、操作系统
# 内容协商
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
# 说明:客户端支持的MIME类型,q值表示优先级
# 来源页面
Referer: http://localhost:8080/05_web_tomcat/login.html
# 说明:当前请求的来源页面,用于防盗链、统计分析
# 压缩支持
Accept-Encoding: gzip, deflate, br
# 说明:客户端支持的压缩算法
# 语言偏好
Accept-Language: zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7
# 说明:客户端语言偏好,支持国际化
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
3. GET 请求的应用场景
| 场景 | 示例 | 特点 |
|---|---|---|
| 页面访问 | GET /index.html | 获取静态资源 |
| 数据查询 | GET /api/users?page=1&size=10 | 查询用户列表 |
| 搜索功能 | GET /search?q=java&type=tutorial | 搜索相关内容 |
| 资源下载 | GET /download/file.pdf | 下载文件资源 |
4. GET 请求安全注意事项
安全提醒
- GET 请求参数在 URL 中可见,不适合传输敏感信息
- 浏览器和服务器对 URL 长度有限制(通常 2KB-8KB)
- 请求会被浏览器缓存,可能泄露用户隐私
# 3.2.4 POST 请求深度分析
POST 请求特征:
POST 方法用于向服务器提交数据,可能会修改服务器状态,支持更复杂的数据传输。
1. POST 请求行
POST /05_web_tomcat/login_success.html HTTP/1.1
与 GET 不同,POST 请求的 URL 通常不包含查询参数。
2. POST 特有请求头
# 内容长度
Content-Length: 31
# 说明:请求体的字节长度,服务器据此读取完整数据
# 缓存控制
Cache-Control: max-age=0
# 说明:不使用缓存,确保数据时效性
# 请求来源
Origin: http://localhost:8080
# 说明:请求的源域,用于CORS安全检查
# 内容类型
Content-Type: application/x-www-form-urlencoded
# 说明:请求体的数据格式,告诉服务器如何解析数据
# 会话标识
Cookie: JSESSIONID=ABC123456789
# 说明:会话跟踪标识符,维持用户状态
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
3. 常见 Content-Type 类型
| Content-Type | 用途 | 数据格式 |
|---|---|---|
application/x-www-form-urlencoded | 表单提交 | key1=value1&key2=value2 |
application/json | API 数据交换 | {"name": "value", "key": "data"} |
multipart/form-data | 文件上传 | 二进制数据+表单字段 |
text/plain | 纯文本 | 原始文本内容 |
application/xml | XML 数据 | <root><data>value</data></root> |
4. POST 请求体示例
# 表单数据格式
username=admin&password=1232131
# JSON 格式(现代API常用)
{
"username": "admin",
"password": "1232131",
"rememberMe": true
}
# XML 格式
<?xml version="1.0" encoding="UTF-8"?>
<login>
<username>admin</username>
<password>1232131</password>
</login>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
5. POST vs GET 对比分析
| 特性 | GET | POST |
|---|---|---|
| 数据位置 | URL 查询字符串 | 请求体 |
| 数据大小 | 受 URL 长度限制(~2KB) | 无严格限制(取决于服务器配置) |
| 安全性 | 数据可见,相对不安全 | 数据隐藏,相对安全 |
| 缓存 | 浏览器会缓存 | 通常不缓存 |
| 书签 | 可以保存为书签 | 无法保存为书签 |
| 后退/刷新 | 无副作用 | 可能重复提交数据 |
| 幂等性 | 幂等操作 | 非幂等操作 |
| 使用场景 | 查询、获取数据 | 提交、修改数据 |
# 3.2.5 HTTP 响应报文详解
响应报文是服务器向客户端返回的数据包,包含处理结果和相关信息
响应报文格式:
响应行: 协议版本 状态码 状态描述
响应头: Header-Name: Header-Value
空行:
响应体: 实际数据内容
2
3
4
1. 响应行分析
HTTP/1.1 200 OK
│ │ │
│ │ └─ 状态描述(可选)
│ └─ 状态码
└─ 协议版本
2
3
4
5
2. 重要响应头详解
# 服务器信息
Server: Apache-Coyote/1.1
# 说明:服务器软件类型和版本
# 范围请求支持
Accept-Ranges: bytes
# 说明:服务器支持按字节范围请求,用于断点续传
# 缓存验证
ETag: W/"157-1534126125811"
# 说明:资源的唯一标识符,用于缓存验证
# 最后修改时间
Last-Modified: Mon, 13 Aug 2018 02:08:45 GMT
# 说明:资源最后修改时间,用于缓存控制
# 内容类型
Content-Type: text/html; charset=UTF-8
# 说明:响应体的MIME类型和字符编码
# 内容长度
Content-Length: 157
# 说明:响应体的字节长度
# 响应时间
Date: Mon, 13 Aug 2018 02:47:57 GMT
# 说明:服务器生成响应的时间
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
3. 响应体内容
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>登录成功页面</title>
</head>
<body>
<h1>恭喜你,登录成功了...</h1>
<p>欢迎使用我们的系统!</p>
</body>
</html>
2
3
4
5
6
7
8
9
10
11
# 3.2.6 HTTP 状态码深度解析
状态码是服务器向客户端传达处理结果的重要机制,帮助客户端理解请求的处理状态。
核心状态码含义:
状态码设计理念
HTTP 状态码采用三位数字设计,第一位数字表示响应类别,后两位提供具体信息。
1. 常用状态码详解
| 分类 | 状态码 | 名称 | 含义 | 应用场景 | 关键头交互 |
|---|---|---|---|---|---|
| 成功 | 200 | OK | 请求成功 | 正常的 GET/POST 请求 | 可伴随缓存头 ETag/Cache-Control |
| 成功 | 201 | Created | 资源创建成功 | REST API 创建资源 | Location 指向新资源 URI |
| 成功 | 204 | No Content | 成功但无响应体 | DELETE/PUT 更新无需返回内容 | 客户端不应再渲染主体 |
| 重定向 | 301 | Moved Permanently | 永久重定向 | 网站结构调整 | 浏览器缓存并更新书签 |
| 重定向 | 302 | Found | 临时重定向 | 临时页面跳转 | 不缓存目标,继续使用旧 URI |
| 重定向 | 304 | Not Modified | 未修改,使用缓存 | 静态资源缓存 | 响应体省略,节省带宽 |
| 客户端错误 | 400 | Bad Request | 请求语法错误 | 参数格式错误 | 返回错误描述 JSON 便于调试 |
| 客户端错误 | 401 | Unauthorized | 需要身份验证 | 登录验证失败 | 搭配 WWW-Authenticate 头 |
| 客户端错误 | 403 | Forbidden | 禁止访问 | 权限不足 | 不泄露具体权限策略 |
| 客户端错误 | 404 | Not Found | 资源不存在 | URL 路径错误 | 可返回统一错误页 |
| 客户端错误 | 405 | Method Not Allowed | 方法不允许 | GET 请求 POST 接口 | 伴随 Allow 列出支持方法 |
| 服务器错误 | 500 | Internal Server Error | 服务器内部错误 | 程序代码异常 | 记录日志不暴露内部堆栈 |
| 服务器错误 | 502 | Bad Gateway | 网关错误 | 代理服务器问题 | 可标记健康检查失败 |
| 服务器错误 | 503 | Service Unavailable | 服务不可用 | 服务器维护 | Retry-After 告知恢复时间 |
2. 状态码分类详解
1xx - 信息性状态码
- 100 Continue:客户端应继续发送请求
- 101 Switching Protocols:协议切换(如升级到 WebSocket)
2xx - 成功状态码
- 200 OK:标准成功响应
- 202 Accepted:请求已接受,但处理未完成
- 204 No Content:成功处理,但无返回内容
3xx - 重定向状态码
- 301 Moved Permanently:永久重定向,更新书签
- 302 Found:临时重定向,保持原 URL
- 304 Not Modified:资源未修改,使用缓存
4xx - 客户端错误状态码
- 400 Bad Request:请求格式错误
- 401 Unauthorized:需要身份验证
- 403 Forbidden:权限不足
- 404 Not Found:资源不存在
5xx - 服务器错误状态码
- 500 Internal Server Error:服务器内部错误
- 502 Bad Gateway:上游服务器错误
- 503 Service Unavailable:服务暂时不可用
设计建议:
- API 统一错误响应结构 (code/message/details);状态码语义与业务错误码分层。
- 避免滥用 200 + 自定义错误字段;应使用合适 4xx/5xx 提升客户端可读性。
- 条件 GET 与缓存配合:正确返回 304 减少带宽。
- 幂等操作 (PUT/DELETE) 在失败时返回明确码 (如 409 冲突)。
# 3.2.7 实际开发应用场景
1. RESTful API 设计
# 获取用户列表
GET /api/users HTTP/1.1
Accept: application/json
# 响应
HTTP/1.1 200 OK
Content-Type: application/json
[{"id": 1, "name": "张三"}, {"id": 2, "name": "李四"}]
# 创建新用户
POST /api/users HTTP/1.1
Content-Type: application/json
{"name": "王五", "email": "wangwu@example.com"}
# 响应
HTTP/1.1 201 Created
Location: /api/users/3
{"id": 3, "name": "王五", "email": "wangwu@example.com"}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2. 文件上传处理
POST /upload HTTP/1.1
Content-Type: multipart/form-data; boundary=----WebKitFormBoundary7MA4YWxkTrZu0gW
Content-Length: 12345
------WebKitFormBoundary7MA4YWxkTrZu0gW
Content-Disposition: form-data; name="file"; filename="document.pdf"
Content-Type: application/pdf
[二进制文件数据]
------WebKitFormBoundary7MA4YWxkTrZu0gW--
2
3
4
5
6
7
8
9
10
3. 缓存策略实现
# 客户端请求
GET /api/data HTTP/1.1
If-None-Match: "686897696a7c876b7e"
# 服务器响应(资源未变化)
HTTP/1.1 304 Not Modified
ETag: "686897696a7c876b7e"
Cache-Control: max-age=3600
2
3
4
5
6
7
8
4. 错误处理最佳实践
# 客户端错误
HTTP/1.1 400 Bad Request
Content-Type: application/json
{
"error": "validation_failed",
"message": "用户名不能为空",
"details": {
"field": "username",
"code": "REQUIRED"
}
}
# 服务器错误
HTTP/1.1 500 Internal Server Error
Content-Type: application/json
{
"error": "internal_server_error",
"message": "服务器暂时无法处理请求",
"requestId": "req-123456789"
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 3.2.8 HTTP 状态码完整参考表
详细状态码列表:
| 状态码 | 状态码英文描述 | 中文含义 |
|---|---|---|
| 1xx | 信息性状态码 | 服务器接收到请求,需要请求者继续执行操作 |
| 100 | Continue | 继续。客户端应继续其请求 |
| 101 | Switching Protocols | 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到 HTTP 的新版本协议 |
| 2xx | 成功状态码 | 操作被成功接收并处理 |
| 200 | OK | 请求成功。一般用于 GET 与 POST 请求 |
| 201 | Created | 已创建。成功请求并创建了新的资源 |
| 202 | Accepted | 已接受。已经接受请求,但未处理完成 |
| 203 | Non-Authoritative Information | 非授权信息。请求成功。但返回的 meta 信息不在原始的服务器,而是一个副本 |
| 204 | No Content | 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档 |
| 205 | Reset Content | 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域 |
| 206 | Partial Content | 部分内容。服务器成功处理了部分 GET 请求 |
| 3xx | 重定向状态码 | 需要进一步的操作以完成请求 |
| 300 | Multiple Choices | 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 |
| 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新 URI,返回信息会包括新的 URI,浏览器会自动定向到新 URI。今后任何新的请求都应使用新的 URI 代替 |
| 302 | Found | 临时移动。与 301 类似。但资源只是临时被移动。客户端应继续使用原有 URI |
| 303 | See Other | 查看其它地址。与 301 类似。使用 GET 和 POST 请求查看 |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 305 | Use Proxy | 使用代理。所请求的资源必须通过代理访问 |
| 306 | Unused | 已经被废弃的 HTTP 状态码 |
| 307 | Temporary Redirect | 临时重定向。与 302 类似。使用 GET 请求重定向 |
| 4xx | 客户端错误状态码 | 客户端错误,请求包含语法错误或无法完成请求 |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面 |
| 405 | Method Not Allowed | 客户端请求中的方法被禁止 |
| 406 | Not Acceptable | 服务器无法根据客户端请求的内容特性完成请求 |
| 407 | Proxy Authentication Required | 请求要求代理的身份认证,与 401 类似,但请求者应当使用代理进行授权 |
| 408 | Request Time-out | 服务器等待客户端发送的请求时间过长,超时 |
| 409 | Conflict | 服务器完成客户端的 PUT 请求时可能返回此代码,服务器处理请求时发生了冲突 |
| 410 | Gone | 客户端请求的资源已经不存在。410 不同于 404,如果资源以前有现在被永久删除了可使用 410 代码,网站设计人员可通过 301 代码指定资源的新位置 |
| 411 | Length Required | 服务器无法处理客户端发送的不带 Content-Length 的请求信息 |
| 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
| 413 | Request Entity Too Large | 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个 Retry-After 的响应信息 |
| 414 | Request-URI Too Large | 请求的 URI 过长(URI 通常为网址),服务器无法处理 |
| 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
| 416 | Requested range not satisfiable | 客户端请求的范围无效 |
| 417 | Expectation Failed | 服务器无法满足 Expect 的请求头信息 |
| 5xx | 服务器错误状态码 | 服务器在处理请求的过程中发生了错误 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的 Retry-After 头信息中 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的 HTTP 协议的版本,无法完成处理 |